
本次课程给大家带来的是很多人都看过很多遍的图,简直是作品集分析图装批利器的图。是不是看起来很酷炫?

在正式进入教程之前,容我先吐个槽,老实说,我不大喜欢这些所谓的数据可视化图,虽然数据可视化本质上是没有错的,但在我看来这些图更多时候更加接近图形设计,因为数据可视化本质上是为了降低人对数据的阅读难度,让人能直观感受到数据上的差别。比如说下面的立体饼状图,再直观不过了。

但是我看过很多的建筑师做的数据可视化的图,那真的是,真的是太好看了,但是除了好看之外就·····啥都看不出来了。比如下图······瞎了瞎了。

数据可视化的初衷,是可视化,可视化的目标是为了直观阅读。除此之外,数据可视化还有一个重点,那就是数据。没有数据哪来的可视化?可数据哪里来呢?尤其是现在早已成熟到杀熟的大数据。都得靠代码来爬去,自己人为统计也可以,但是会疯的,而代码恰恰是大部分建筑师的软肋,所以很多图里的数据都是····意淫的。
然而说这么多又有什么用呢?我们就是要好看的图啊!这是个看颜值的社会!图好看才能让人继续看下去嘛~~ok~那咱们今天的教程就来满足你。
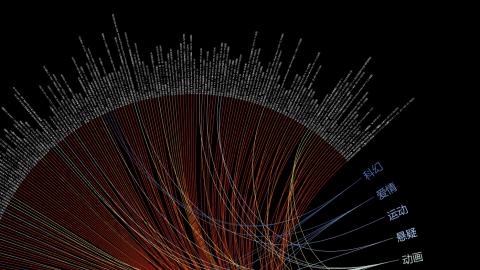
那咱们就进入今天的教程,首先起因是看到了这张图:

这张图的作者,在2012年看了365部电影,然后根据电影的类型分类做了个数据可视化,根据这张图可以看出,某种类型的电影看的越多,线就越多,大概可以看出,作者不喜欢看战争,体育,历史和法庭片,总之想看清楚就必须放的很大才行。
OK,那我们就仿照他的思路来吧,也去找电影,数据哪里来呢?很遗憾我也不会代码,不会去爬数据,不过没关系呀,有人家现成的爬好的数据,随便一搜就get了一个《豆瓣电影网-所有电影列表-爬取数据》,里面把豆瓣网的电影信息都爬下来了,我们就可以愉快的直接用而不是数据造假了。

现在的社会是大数据的社会,到处都是数据,发挥了相当大的作用,不论是杀熟啊,还是诱导消费啊,还是········不过关于大数据·····说个笑话

所以数据不能乱分析的,会闹笑话的
ok,拿到这个数据之后我们就可以开始干活了。第一个问题是怎么样把这个excel的数据拾取进GH,好在我们有很多的插件可以做这个事儿。我们这里就直接用大家都有的Lunchbox插件里的Excel read运算器,指定好路径就可以直接读取了,方便得很。

然后根据数据结构的拆解我们就可以得到每个类型的数据了,包括评分,片名,投票人数,类型,产地,上映时间,时长等等都可以直接获得。

既然数据有了接下来就是如何处理了。由于图形分两部分,一部分是电影类型,一部分是电影名字。

然后把电影名称分布在线上即可,注意得求一下文字的工作平面

电影名称也是同理,可以均不再曲线上即可。

最后再把二者混接曲线就得到中间的线了。

最后用human的预览给线着色即可

怎么样?是不是很简单?啥?还是不会?那就来一起看视频吧~
DLC:多类别连线

